
 Two hundred years after the first Battle of New Orleans, we had the third, and perhaps most important, tussle the city has ever seen. I refer, of course, to the SC14 Student Cluster Competition.
Two hundred years after the first Battle of New Orleans, we had the third, and perhaps most important, tussle the city has ever seen. I refer, of course, to the SC14 Student Cluster Competition.
This is the seventh time that university students have battled each other to see which team can field a cluster that can dominate all others – while staying under the 3,000 watt power cap. If you’re not familiar with how these competitions work, this will bring you up to speed. We’ll wait while you catch up…
(Side note: The original 1814 Battle of New Orleans effectively ended the War of 1812. American rebels, led by General Andrew Jackson — with an assist from French semi-pirate Jean Laffite — achieved a solid victory over the British. I recommend listening to this authoritative account, the Johnny Horton song “The Battle of New Orleans.” What ever happened to songwriter/historians?)
This was the biggest “Big Iron” face-off in SC competition history, and the most varied. Twelve teams from seven countries brought their best to New Orleans, and all had high hopes of snagging either the Highest LINPACK crown or the coveted Overall Champion trophy. (Even though there are no actual crowns or trophies.)
As usual, we saw a wide variety of systems and configurations from the student teams. Here’s the big picture (click image to enlarge):
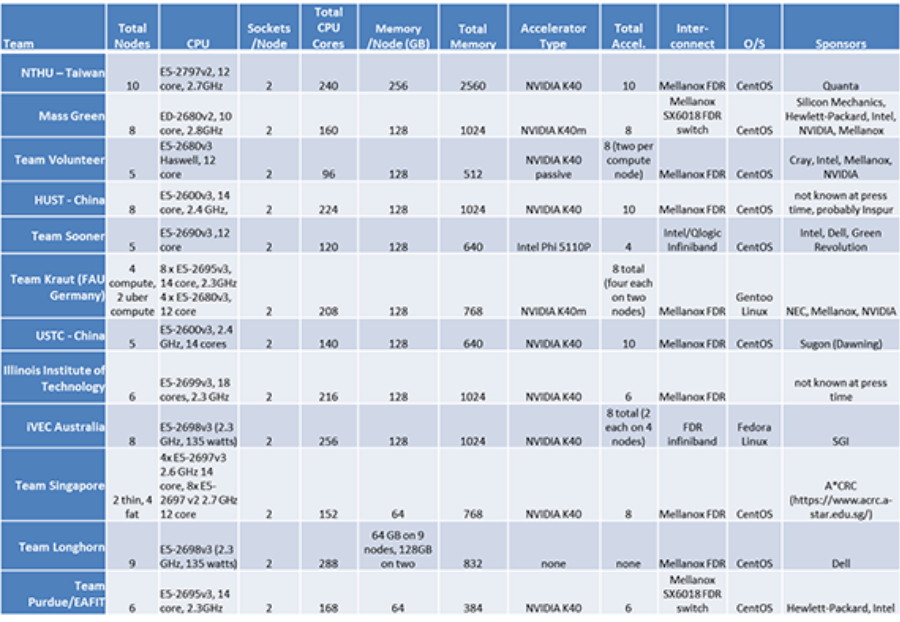
However, as we’ve seen in past competitions, the hardware doesn’t determine the winners. Experience, planning, grace under pressure, sponsor support, and plain hard work is what separates the championship teams from the other competitors.
With that in mind, here’s our look at the SC14 Cluster Competition field, starting with the heavyweights – at least in terms of cluster size…
![]() Team Taiwan (National Tsing Hua University, Taiwan) looks to have the biggest cluster overall with 240 CPU cores, 10 NVIDIA K40 GPUs, and a massive 2.5 TB of memory. Is it possible to run this whole configuration at full speed and stay anywhere near the 3,000 watt power cap? No way. But they know this, and they’re counting heavily on their skill at throttling down their CPUs or GPUs to maximize performance while staying under the power limit.
Team Taiwan (National Tsing Hua University, Taiwan) looks to have the biggest cluster overall with 240 CPU cores, 10 NVIDIA K40 GPUs, and a massive 2.5 TB of memory. Is it possible to run this whole configuration at full speed and stay anywhere near the 3,000 watt power cap? No way. But they know this, and they’re counting heavily on their skill at throttling down their CPUs or GPUs to maximize performance while staying under the power limit.
This isn’t Team Taiwan’s first cluster rodeo. They’ve competed in seven prior competitions, including bouts at the Asian student cluster competition. Over the years they’ve taken home two Overall Championships plus two Highest LINPACK awards. Given their impressive configuration and equally impressive competition track record, Team Taiwan has earned their status as an elite student cluster team.
![]() Team Quokka (iVEC, Australia) is another heavy weight competitor at SC14. Their 8-node configuration contains 256 CPU cores, eight Tesla K40 GPUs, and a terabyte of memory. In past competitions, teams have tended to spread their GPUs out evenly among their compute nodes. This year we’re seeing more teams concentrate these accelerators on fewer nodes, so that when the GPUs aren’t needed, more of the overall configuration can be idled to save precious power.
Team Quokka (iVEC, Australia) is another heavy weight competitor at SC14. Their 8-node configuration contains 256 CPU cores, eight Tesla K40 GPUs, and a terabyte of memory. In past competitions, teams have tended to spread their GPUs out evenly among their compute nodes. This year we’re seeing more teams concentrate these accelerators on fewer nodes, so that when the GPUs aren’t needed, more of the overall configuration can be idled to save precious power.
This is the second time the Aussies have traveled to America to test their cluster prowess against the rest of the world. In their rookie year, at SC13 in Denver, the team finished in the middle of the pack. The 2014 edition of Team Quokka has an entirely new set of students but the same coach, which has definitely helped the team take advantage of past lessons learned.
If there were a category for the team that brings the greatest number of stuffed animal mascots, the Aussies would have won that award twice over. Unfortunately, this isn’t a prize category this year, although that’s been proposed (by me) for SC15.
![]() Team Longhorn (The University of Texas at Austin) has the opportunity to make Student Cluster Competition history by becoming the first team to ‘three-peat’ as SC cluster champion. Only one other team, NTHU from Taiwan, has ever had this chance, and they came just short of the goal at SC12 in Salt Lake City.
Team Longhorn (The University of Texas at Austin) has the opportunity to make Student Cluster Competition history by becoming the first team to ‘three-peat’ as SC cluster champion. Only one other team, NTHU from Taiwan, has ever had this chance, and they came just short of the goal at SC12 in Salt Lake City.
The Texas system this year is a departure from their winning 2013 and 2012 configurations. In those systems, the Longhorns went with a mix of CPUs and GPUs, running four Teslas in 2013. But their 2014 box is total old-school with 18 E5-2698v3 16-core processors backed up by almost a terabyte of memory. No fuel injection, turbocharging, or any other fancy stuff.
With this move, they essentially gave up on winning the LINPACK award in hopes that their traditional box would be able to outperform the hybrids on the scientific applications. Given their skills, experience, and backing from TACC (Texas Advanced Computing Center) and sponsor Dell, Team Longhorn has to be considered one of the favorites to win the SC14 Overall Championship. But making the hat trick is never easy.
![]() Team Mass Green (The Massachusetts Green High Performance Computing Center: MIT, Harvard, Northeastern University, and Boston University) has had a busy year of student cluster competitions. Fresh off their appearance at ISC’14 in Leipzig, Team Green has once again jumped into the SC cluster competition fray. This is the fifth time a Mass Green team has competed in a major event, which is pretty cool.
Team Mass Green (The Massachusetts Green High Performance Computing Center: MIT, Harvard, Northeastern University, and Boston University) has had a busy year of student cluster competitions. Fresh off their appearance at ISC’14 in Leipzig, Team Green has once again jumped into the SC cluster competition fray. This is the fifth time a Mass Green team has competed in a major event, which is pretty cool.
As usual, the Beantowners are bringing a whole lot of gear. Their 2014 dreadnought has 8 nodes, each with dual 10-core E5-2680v3 CPUs running at 2.8 GHz. For deck guns, they have 8 NVIDIA K40m (passively cooled) GPUs, which will give them additional processing punch for LINPACK and some of the scientific applications.
While their system is pretty conventional this year, Team Mass Green doesn’t shy away from experimentation. They were the first team to try fat quad-socket nodes in a cluster competition (ISC’14). Though unsuccessful, it was worth the attempt.
On the creepier side, Mass Green was the first (and only) team that used identical twin team members in an attempt to harness their natural biological link to attain higher cluster performance.
![]() Team HUST (Huazhong University of Science and Technology, China) is another veteran team. SC14 marks their fourth major cluster competition. They parlayed a second-place finish at China’s first ASC competition in 2013 to win a berth at ISC’13 in Leipzig, where they won the LINPACK award with a (then) recording-setting 8.455 TFlop score.
Team HUST (Huazhong University of Science and Technology, China) is another veteran team. SC14 marks their fourth major cluster competition. They parlayed a second-place finish at China’s first ASC competition in 2013 to win a berth at ISC’13 in Leipzig, where they won the LINPACK award with a (then) recording-setting 8.455 TFlop score.
Their exact configuration in the table above is based on my interview with the team and observations of what they’ve run before. In all the hubbub surrounding SC14, somehow HUST’s final detailed architectural proposal wasn’t received by the committee.
We do know enough to place HUST into the heavyweight class. Their eight-node, 224-core box is definitely one of the largest clusters in the competition this year. Add in a terabyte of memory, plus 10 NVIDIA K40 GPU cards, and you’ve got a pretty powerful stew of compute power.
Cruiserweights Represent
The rest of the field may have somewhat smaller systems in terms of node count, but they’re still packing more than enough compute to top the 3,000 watt power cap and perhaps nab the LINPACK or Overall Championship crowns. Let’s take a closer look…
![]() Team IIT (Illinois Institute of Technology) is a first-time competitor at SC14. Located in Chicago, IIT was the result of a 1940 merger of the Armour Institute of Technology (founded in 1890) and Lewis Institute. Both of these schools had nationally ranked engineering programs. I would assume that the Armour Institute mainly focused on engineering better beef and pork products – designing new classes of canned hams and bologna that can, for example, handle particularly harsh environments or high-impact events.
Team IIT (Illinois Institute of Technology) is a first-time competitor at SC14. Located in Chicago, IIT was the result of a 1940 merger of the Armour Institute of Technology (founded in 1890) and Lewis Institute. Both of these schools had nationally ranked engineering programs. I would assume that the Armour Institute mainly focused on engineering better beef and pork products – designing new classes of canned hams and bologna that can, for example, handle particularly harsh environments or high-impact events.
Team IIT has packed quite a cluster sack lunch for their first outing at SC14. They were originally going to use an eight-node heavyweight system, but one of their nodes literally melted down during testing (with smoke and all), taking it out of play.
After some rejiggering, the team went forward with a six-node box loaded with twelve 18-core Intel E5-2699v3 processors running at 2.3GHz. They’re buttressing these 216 CPU cores with six NVIDIA Tesla GPUs – sort of like an extra helping of flavorful pimentos in their salami.
Team IIT is also making a bit of history. They are the first team to include a female high school student as a member. You’ll meet her and the rest of the team in their upcoming introductory video; stay tuned for that.
![]() Team Sooner (University of Oklahoma) had to show up sooner or later in an SC cluster competition (bad pun, but true). Anyone who follows U.S. college sports knows that the University of Texas and the University of Oklahoma are bitter rivals. Their annual football game, dubbed the Red River Rivalry, is played in Dallas – exactly halfway between the two campuses. Fans split up in the stadium, with burnt orange Longhorn supporters on one side and red-clad Sooner fans on the other, separated by electrified razor wire and security forces packing mace cannons. These people just don’t get along.
Team Sooner (University of Oklahoma) had to show up sooner or later in an SC cluster competition (bad pun, but true). Anyone who follows U.S. college sports knows that the University of Texas and the University of Oklahoma are bitter rivals. Their annual football game, dubbed the Red River Rivalry, is played in Dallas – exactly halfway between the two campuses. Fans split up in the stadium, with burnt orange Longhorn supporters on one side and red-clad Sooner fans on the other, separated by electrified razor wire and security forces packing mace cannons. These people just don’t get along.
So with the Texas Longhorns on a successful two-year run as SC cluster champion, it’s bound to attract the attention of the Sooners, who have a burning desire to dethrone them.
Team Sooner definitely came to play, and they’re taking a page out of the Longhorn playbook. Their first competition configuration uses the Green Revolution immersion cooling solution that Texas used in the 2011 Battle of Seattle.
However, Oklahoma is going at it in a slightly different way. They’re using the big Green Revolution mineral oil trough, but only filling it with five nodes, each equipped with dual 12-core Intel E5 CPUs, plus four Intel Phi co-processors.
The Team Sooner gear only takes up maybe a third of their mineral oil-filled vat capacity, giving them a much higher liquid-to-hardware ratio than design specs for the enclosure. The Sooner see this giving them an edge over the competition, figuring that the greater liquid volume means they won’t have to run the liquid pumps and radiator fans much, if at all, which means more power for computing rather than cooling.
In the upcoming “Meet Team Sooner” video, you’ll see their configuration and hear our discussion of how this might play in their favor.
![]() Team Kraut (Friedrich-Alexander-Universitat, Germany) isn’t politically correct, but they’re a lot of fun, and they know their HPC too. They picked the name “Team Kraut” themselves and are using it on their competition paperwork. This alone makes them at least 27% funnier than most other Germans.
Team Kraut (Friedrich-Alexander-Universitat, Germany) isn’t politically correct, but they’re a lot of fun, and they know their HPC too. They picked the name “Team Kraut” themselves and are using it on their competition paperwork. This alone makes them at least 27% funnier than most other Germans.
This is the second time Team Kraut has made a run at the SC cluster cup. They learned a lot from their 2013 outing, and it shows in their cluster and approach to the competition.
Last year, the team had a behemoth cluster with a raft of cores and heaps of GPUs. While they had a respectable finish, they realized that their “everything plus the kitchen sink” approach might not be the winning strategy.
This year, the team showed up with a sophisticated six-node design that mixes four regular compute nodes (or Kompute Nodestats) with two uber compute nodes (or Uber Kompute Nodestats).
The regular compute nodes feature dual E5 14-core processors running at 2.3GHz, with 128 GB memory per node – straightforward stuff. The two uber nodes are where things get interesting. Each uber node is equipped with dual E5 12-core processors running at a higher 2.8GHz frequency than the CPUs in the regular nodes. The two uber nodes are also decked out with four NVIDIA Tesla GPUs each, which is a lot of concentrated GPU goodness.
This configuration gives the team the ability to push GPU-centric apps onto the uber nodes, while using the traditional regular nodes for standard non-CUDA-ized codes. When they’re not running GPU-centric apps, they can idle the uber nodes and crank up the compute power on their CPU-only regular nodes.
It’s an interesting approach and has some merits – but, I think, is highly dependent on the application mix between GPU-centric and CPU-only workloads. If there’s a healthy mix of the two, Team Kraut will be able to run the apps in a way that maximizes their cluster utilization. But if the mix skews strongly in one direction or the other, then all bets are off.
![]() Team USTC (University of Science and Technology of China) is fresh off an impressive debut performance at ISC’14 last June. As the new kids on the block in Leipzig, there wasn’t a lot expected of them. (Much like also-unheralded 1990s German boy band “Leipzig Boys on the Block.” Their first single, “Teuton Minen Own Horn” never made the charts. Although I think that Robbie Williams did cover it eventually. But we digress…)
Team USTC (University of Science and Technology of China) is fresh off an impressive debut performance at ISC’14 last June. As the new kids on the block in Leipzig, there wasn’t a lot expected of them. (Much like also-unheralded 1990s German boy band “Leipzig Boys on the Block.” Their first single, “Teuton Minen Own Horn” never made the charts. Although I think that Robbie Williams did cover it eventually. But we digress…)
However, unlike the doomed L-Boys, USTC did much better than anticipated at their first student cluster competition. They finished just behind Overall Championship winner South Africa and barely ahead of the much more experienced Team Tsinghua to grab a second place slot.
At the ISC competition in June, the USTC’ers were driving a heavyweight ten-node, eight-K40 GPU behemoth. In a surprise move, they’ve radically changed their system for SC14 – going with five nodes of Sugon’s latest liquid-cooled kit, sporting 14-core Xeon E5 processors (140 total cores) clocked at 2.4 GHz, with 640 GB RAM and ten NVIDIA K40 GPUs.
This configuration potentially packs quite a punch, provided that the USTC kids are able to optimize the applications for use with GPUs.
![]() Team Calderero (Purdue/EAFIT) consists of students from Purdue University in the U.S.A. and Universidad EAFIT, a private university located in Medellin, Colombia. Purdue is no stranger to student cluster competitions, but it’s an entirely new experience for their comrades in arms from Colombia.
Team Calderero (Purdue/EAFIT) consists of students from Purdue University in the U.S.A. and Universidad EAFIT, a private university located in Medellin, Colombia. Purdue is no stranger to student cluster competitions, but it’s an entirely new experience for their comrades in arms from Colombia.
Purdue certainly could have raised a cluster team of their own; they’ve done it eight times before. But this year, they decided to reach out to their sister school and pull them into the fray. From all accounts, it’s been a great partnership, with the Colombians bringing both enthusiasm and solid technical skills to the team. More importantly, EAFIT’s participation has spurred greater interest in HPC among its faculty and students.
Hardware wise, the Purdue/EAFIT team brought a modest 6-node, 168-core system, with only 64 GB of memory per node. Although this sounds a little light, La Boilermakers crammed six NVIDIA Tesla K40 GPUs into their cluster. This is the first time any Purdue team has deployed GPUs in a competition system. I get the sense that this is more of an experiment than a full-fledged competitive move.
More than perhaps any other school, Purdue has used their participation in the cluster competitions to build up both their HPC course offerings and student interest in becoming HPC ninjas. (Note: computer science graduates from Purdue don’t have the term “HPC Ninja” on their sheepskins. They don’t receive actual sheepskins either, for that matter.)
I recorded an interview with Dr. Gerry McCartney, Purdue CIO, in which we discussed how Purdue has leveraged the cluster competitions to enhance their HPC classroom offerings and enrich the student experience. It’ll be posted in my HPC column soon…
![]() Team Singapore (National University of Singapore) is a first-time competitor in the student cluster wars. While we haven’t seen this team before, and thus don’t know much about them, they did submit one of the finest architectural proposals I’ve seen.
Team Singapore (National University of Singapore) is a first-time competitor in the student cluster wars. While we haven’t seen this team before, and thus don’t know much about them, they did submit one of the finest architectural proposals I’ve seen.
It’s clear that the team has put a lot of thought into their cluster configuration. Their architectural doc discussed in detail how they made their processor, memory, node, and accelerator decisions. Very well done on their part.
The result? A six-node cluster that’s composed of two ‘thin’ and four ‘fat’ nodes. A thin node uses dual 14-core Xeon E5-2697 v3 CPUs, and a fat node is configured with dual 12-core Xeon E5-2697 v2 CPUs. What makes the fat nodes fat is the addition of dual NVIDIA K40 GPUs to goose their compute performance.
As they said in their proposal, the system is designed to provide high performance on both CPU-only and GPU-friendly codes. The team aimed to have a cluster with enough CPU power to perform well on less accelerator-friendly applications like ADCIRC.
The real key for Team Singapore, like most of the other teams, will be how well they are able to control their power usage. According to the team, just the CPU portion of their cluster pulls almost 2,700 watts. Adding GPUs to the mix, at 234 watts each, will require the team to idle some CPUs, which requires a delicate and perilous balancing act in the midst of the competition.
![]() Team Volunteer (University of Tennessee, Knoxville) returned for a second try at the SC cluster crown. Their first attempt was less than auspicious. Hardware problems forced the team to rebuild their entire system during the competition. This is like making a stock car team swap out transmissions in the middle of a race. Tennessee had a good team, but couldn’t prove it at SC13.
Team Volunteer (University of Tennessee, Knoxville) returned for a second try at the SC cluster crown. Their first attempt was less than auspicious. Hardware problems forced the team to rebuild their entire system during the competition. This is like making a stock car team swap out transmissions in the middle of a race. Tennessee had a good team, but couldn’t prove it at SC13.
Team Volunteer has put the doomed SC13 competition behind them, formed another team, revamped their hardware configuration, and brought it all to New Orleans.
It’s mostly a new crop of kids, so there’s not a lot of competition experience, but I got the feeling that these kids really wanted to prove something this year.
Tennessee has the smallest cluster in the competition, at least in terms of CPU power. It’s a five-node, 96-core system with 512 GB of memory. But the team is swinging with the big guys due to their eight NVIDIA K40 Tesla accelerators.
Something that caught my attention in Tennessee’s final architectural proposal is how they cited their use of application and profiling tools from team sponsor Cray. They also discussed how they stuck closely to tools and operating environments along the lines of their other team sponsor, the U.S. National Institute for Computational Sciences – folks who know their way around a cluster.
Finally, they talked about how the applications this year all GPU ports, which isn’t something that the other teams necessarily found. It looks like the kids from Knoxville have really dug into the innards of the competition applications and like what they see.
Next up will be our first interviews with the teams, then presentations from each team (a new requirement this year), then detailed results and analysis… stay tuned.
Posted In: Latest News, SC 2014 New Orleans
Tagged: supercomputing, Student Cluster Competition, HPC, University of Science and Technology of China, MGHPCC, Purdue University, National Tsing Hua University, Huazhong University of Science & Technology, iVEC, Friedrich-Alexander University of Erlangen-Nuremberg, University of Tennessee, The University of Texas at Austin, SC 2014, Illinois Institute of Technology, University of Oklahoma, Universidad EAFIT, National University of Singapore, Meet the teams